Control de versiones en un Data Lakehouse con Dremio y Project Nessie
¿Qué pensarías si te dijera que puedes usar un control de versiones para los datos tal como lo haces con Git para el código?
La primera vez que vi esto me pareció muy extraño, pero luego de crear un pequeño proyecto para una actividad de mi maestría en Big Data le vi todo el sentido del mundo. El control de versiones de datos es posible gracias a proyectos como Project Nessie1 y a Data Lakehouse como lo es Dremio2
Si hay conceptos o términos nuevos para ti, pronto estaré haciendo blogs explicando a detalle cada uno de esos términos. Te invito a seguirme en mi LinkedIn para estar al tanto.
Consultar los datos en un día en particular no es algo innovador, bases de datos como Snowflake3 y BigQuery4 tienen un sistema parecido llamado Time Travel en el que según como lo hayas configurado puedes consultar tablas al estado en que estaba en cierta cantidad de días u horas en el pasado, sin embargo, estos features están más pensados a casos de emergencia de pérdida de información y así poder recuperarla con facilidad.
Ejecución de la infraestructura en local
El proceso de instrucciones para crear la infraestructura y configurar Dremio se encuentra en github.com/osmandi/data-lakehouse. Donde he usado Podman en lugar de Docker, pero igual se puede con ambos.
Podman es una alternativa a Docker pero rootless y deamonless (crearé un artículo al respecto pronto).
Vamos al código
Ya que tenemos la infraestructura levantada y Dremio configurado, vamos a divertirnos con un poco de código. Para ello entramos en Dremio en http://localhost:9047/ a en la parte de SQL Runner.
Ya una vez allí empezaremos creando la tabla en la rama main en nessie:
CREATE TABLE IF NOT EXISTS nessie.split_keyboards (
model VARCHAR,
total_keys INTEGER
);El paso siguiente será cargar el contenido del CSV que se encuentra en Minio a la tabla que acabamos de crear:
COPY INTO nessie.split_keyboards FROM '@minio/split_keyboards.csv';Consultamos el contenido de la tabla con la siguiente query:
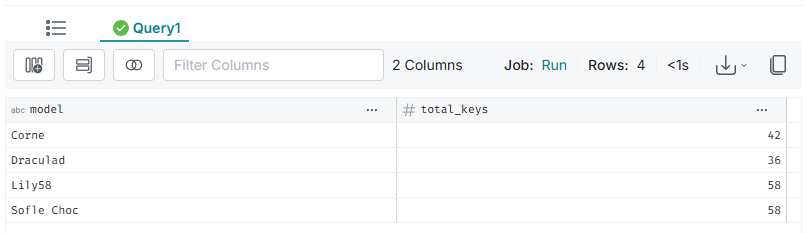
SELECT * FROM nessie.split_keyboards;Dando como resultado la siguiente imagen, en el cual podemos observar que el CSV trata de teclados mecánicos custom y la cantidad de teclas que contienen:
Sin embargo, al analizar el dataset nos dimos cuenta de que el teclado Draculad tiene la opción de colocar 2 potenciómetros (que podrían ser usados para el volumen) en lugar de 2 switches por lo cual la cantidad de switches en total son 34 en vez de 36. Para hacer este ajuste vamos a hacerlo como si estuviéramos usando código con un control de versiones, hacer los cambios en una rama y luego hacer merge con la rama main.
Empezaremos creando la rama:
CREATE BRANCH IF NOT EXISTS less_keys_draculad IN nessie;Y luego haremos el cambio en ese registro cambiando a 34 solo el registro del teclado Draculad:
USE BRANCH less_keys_draculad IN nessie;
UPDATE nessie.split_keyboards SET total_keys = 34 WHERE model = 'Draculad';Vamos a consultar como se ve el registro del teclado Draculad en ambas ramas:
SELECT 'less_keys_draculad' AS "BRANCH", total_keys FROM nessie.split_keyboards AT BRANCH less_keys_draculad WHERE model = 'Draculad'
UNION ALL
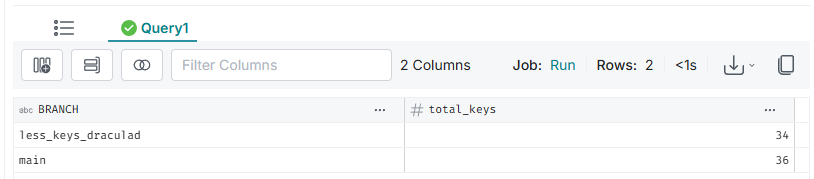
SELECT 'main' AS "BRANCH", total_keys FROM nessie.split_keyboards AT BRANCH main WHERE model = 'Draculad';Dando como resultado la siguiente imagen donde se puede observar que para la rama main total_keys es 36 y para la rama less_keys_draculad es total_keys es 34.
Procedemos hacer el merge con la siguiente query:
MERGE BRANCH less_keys_draculad INTO main IN nessie;Y consultamos la tabla en la rama main:
SELECT *
FROM nessie.split_keyboards AT BRANCH main;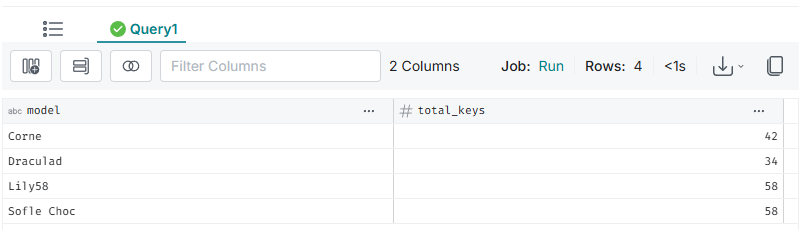
Como puedes observar para el teclado Draculad ya aparece que total_keys es 34 en lugar de 36 como estaba anteriormente. Ahora ¿qué pasaría si quisiéramos ver los cambios que ha tenido una tabla en particular? Para ello nos vamos a Nessie en http://localhost:19120/ y así como hacemos en Git podemos buscar la historia de commits al que podemos hacer SELECT a esos commits y ver cómo estaba la tabla en ese punto así tal cual como se hace en Git.
¿Qué casos de uso puede tener? ✅
Llegados a este punto nos podríamos preguntar para qué tendríamos un control de versiones en los datos y pues serían las mismas que cuando versionamos código de producto:
- Trabajar de forma colaborativa a través de ramas evitando crear esquemas o tablas con alguna nomenclatura.
- Conocer el estado en que estaban los datos en un momento en particular.
- Regresar los datos a un estado anterior de forma sencilla en caso de algún error en los datos.
- Usar los datos como producto.
Si tienes interés en profundizar en este tema, te recomiendo los siguientes recursos:
- Basics of Lakehouse Engineering - Iceberg, Nessie, Dremio (es un curso gratis de Udemy).
- Dremio Docs - Branches